수제 RAG 챗봇에서 Cloudflare AI Search 챗봇으로 갈아탄 기록
직접 만든 RAG 기반 위키 챗봇을 Cloudflare AI Search 기반 구조로 옮기며 겪은 인증, 응답 구조, 결과 수 제한 문제를 정리했다.
앞선 글에서 MkDocs 기반 개인 위키에 LLM 기능을 붙이는 과정을 정리했다.
처음에는 꽤 전형적인 수제 RAG(Retrieval-Augmented Generation) 구조였다. 문서를 직접 읽고, 적당한 크기로 나누고, 임베딩을 만들고, Vectorize에 넣고, 질문이 들어오면 관련 문서를 찾아 LLM에 넘기는 방식이다.
그 구조도 충분히 의미 있었다. 직접 만들어보니 RAG가 어떻게 움직이는지 몸으로 이해할 수 있었다. 하지만 운영 관점에서 보면 손이 많이 갔다.
- 문서 청킹 기준을 계속 조정해야 한다.
- 임베딩과 검색 로직을 직접 관리해야 한다.
- 검색 결과를 다시 프롬프트 문맥으로 조립해야 한다.
- 응답 품질이 흔들리면 어느 단계가 문제인지 계속 추적해야 한다.
그러던 중 Cloudflare가 제공하는 AI Search를 살펴보게 됐다. 문서를 넣고, 검색하고, 필요한 경우 챗봇 응답까지 이어가는 흐름을 Cloudflare 쪽에서 더 높은 수준의 기능으로 제공하고 있었다.
그래서 오늘은 기존 수제 RAG 기반 챗봇을 걷어내고, Cloudflare AI Search 기반 챗봇으로 옮겨봤다.
 내가 직접 엮던 RAG 파이프라인을 Cloudflare AI Search 중심 구조로 단순화해봤다.
내가 직접 엮던 RAG 파이프라인을 Cloudflare AI Search 중심 구조로 단순화해봤다.
왜 갈아타고 싶었나
수제 RAG의 장점은 명확하다. 구조를 내가 통제할 수 있다. 어느 모델로 임베딩할지, 청크를 얼마나 크게 자를지, 검색 결과를 몇 개 가져올지, 프롬프트를 어떻게 만들지 전부 직접 정할 수 있다.
하지만 작은 개인 위키를 계속 키워가는 입장에서는 그 자유도가 곧 운영 부담이 되기도 한다.
내가 원하는 것은 검색 엔진 자체를 만드는 것이 아니라, 내 문서를 바탕으로 질문에 잘 답하는 위키 챗봇이다. 그렇다면 문서 인덱싱, 하이브리드 검색, 검색 결과 정렬 같은 기반 기능은 플랫폼에 맡기고, 나는 위키 경험을 다듬는 쪽에 집중하는 편이 낫다.
Cloudflare AI Search가 매력적으로 보였던 이유가 바로 이 지점이었다.
공식 문서 기준으로 AI Search는 자연어 질의로 관련 결과를 찾거나 AI 생성 응답을 받을 수 있는 검색 기능을 제공한다. REST API는 OpenAI 호환 messages 형식을 사용하고, 검색 API와 챗 completions API를 나눠 쓸 수 있다.
Items API로 문서 넣기
첫 번째 작업은 위키 문서를 AI Search에 넣는 것이었다.
기존에는 파이썬 스크립트에서 문서를 직접 청킹하고, 임베딩 API를 호출하고, Vectorize에 넣었다. 이제는 AI Search의 Items API에 문서를 넣는 방식으로 바꿨다.
예시는 이런 느낌이다. 실제 계정 ID나 토큰은 절대 코드에 직접 남기지 않고 환경변수로 다루는 것이 맞다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import os
import requests
account_id = os.environ["CLOUDFLARE_ACCOUNT_ID"]
api_token = os.environ["CLOUDFLARE_API_TOKEN"]
instance_id = "my-wiki-search"
url = (
f"https://api.cloudflare.com/client/v4/accounts/{account_id}"
f"/ai-search/instances/{instance_id}/items"
)
payload = {
"key": "sample-doc",
"text": "# 문서 제목\n\n위키 문서 본문...",
"metadata": {
"title": "문서 제목",
"path": "/docs/sample-doc/"
}
}
response = requests.put(
url,
headers={
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"
},
json=payload,
timeout=30
)
response.raise_for_status()
이 방식의 장점은 단순하다. 문서를 검색 가능한 항목으로 넣는 책임을 AI Search 쪽에 맡길 수 있다. 수제 RAG에서 내가 직접 붙잡고 있던 많은 단계가 줄어든다.
바인딩 대신 REST API로 우회
처음에는 Workers 또는 Pages Functions에서 바인딩을 통해 AI Search를 호출하려고 했다.
Cloudflare 문서를 보면 ai_search 또는 ai_search_namespaces 바인딩을 설정해 런타임에서 env.AI_SEARCH 형태로 접근할 수 있다. 이 방식이 가장 깔끔해 보였다.
다만 실제 작업 중에는 베타 기능 특유의 불안정함과 설정 이슈가 있었다. 대시보드에서 바인딩을 추가하는 흐름이 매끄럽지 않았고, 당장 챗봇을 완성하는 데 시간이 더 걸릴 것 같았다.
그래서 방향을 바꿨다.
이번에는 Workers에서 Cloudflare AI Search REST API를 직접 호출하는 구조로 갔다. 바인딩보다 조금 더 노출적으로 보일 수는 있지만, HTTP 요청으로 동작을 확인할 수 있어서 디버깅은 오히려 쉬웠다.
인증 오류의 핵심은 Run 권한이었다
가장 시간을 많이 쓴 부분은 인증이었다.
토큰을 만들고, API를 호출했는데 검색 단계에서 계속 인증 오류가 났다. 이상한 점은 엔진이나 인스턴스 조회는 되는데, 실제 검색만 실패한다는 것이었다.
나중에 원인을 찾고 보니 권한이 부족했다.
Cloudflare AI Search REST API는 토큰에 AI Search:Edit와 AI Search:Run 권한이 필요하다. 문서를 넣고 설정을 바꾸는 권한과, 실제 검색 엔진을 실행하는 권한이 분리되어 있는 것이다.
이건 꽤 좋은 보안 모델이다. 다만 처음 만났을 때는 헷갈리기 쉽다.
정리하면 API 토큰에는 최소한 이런 식의 권한이 필요했다.
1
2
Account > AI Search:Edit
Account > AI Search:Run
Edit만 있으면 관리 작업 일부는 될 수 있지만, 검색 실행에서 막힐 수 있다. 나처럼 “조회는 되는데 검색만 안 된다”는 상황을 만나면 가장 먼저 Run 권한을 확인하는 게 좋다.
results가 아니라 chunks일 수 있다
인증을 해결하고 나니 다음 문제는 응답 구조였다.
로컬 테스트에서는 결과 배열을 results라고 생각하고 코드를 짰다. 그런데 실제 Workers 환경에서 받은 응답은 chunks 배열 쪽을 봐야 했다. 메타데이터도 내가 예상한 위치와 다르게 한 겹 안쪽에 들어 있었다.
그래서 파싱 코드를 조금 더 방어적으로 바꿨다.
1
2
3
4
5
6
7
8
9
10
11
12
const searchResults =
searchData.result?.chunks ??
searchData.result?.results ??
[];
const contextText = searchResults.map((result) => {
const metadata = result.item?.metadata ?? result.metadata ?? {};
const title = metadata.title ?? "문서";
const text = result.text ?? result.content?.text ?? "";
return `[출처: ${title}]\n${text}`;
}).join("\n\n");
베타 API나 빠르게 바뀌는 플랫폼 기능을 붙일 때는 이런 안전망이 도움이 된다. 응답 구조 하나가 달라졌다고 챗봇 전체가 “문서를 찾을 수 없다”고 말하면, 사용자 입장에서는 기능이 아예 죽은 것처럼 보이기 때문이다.
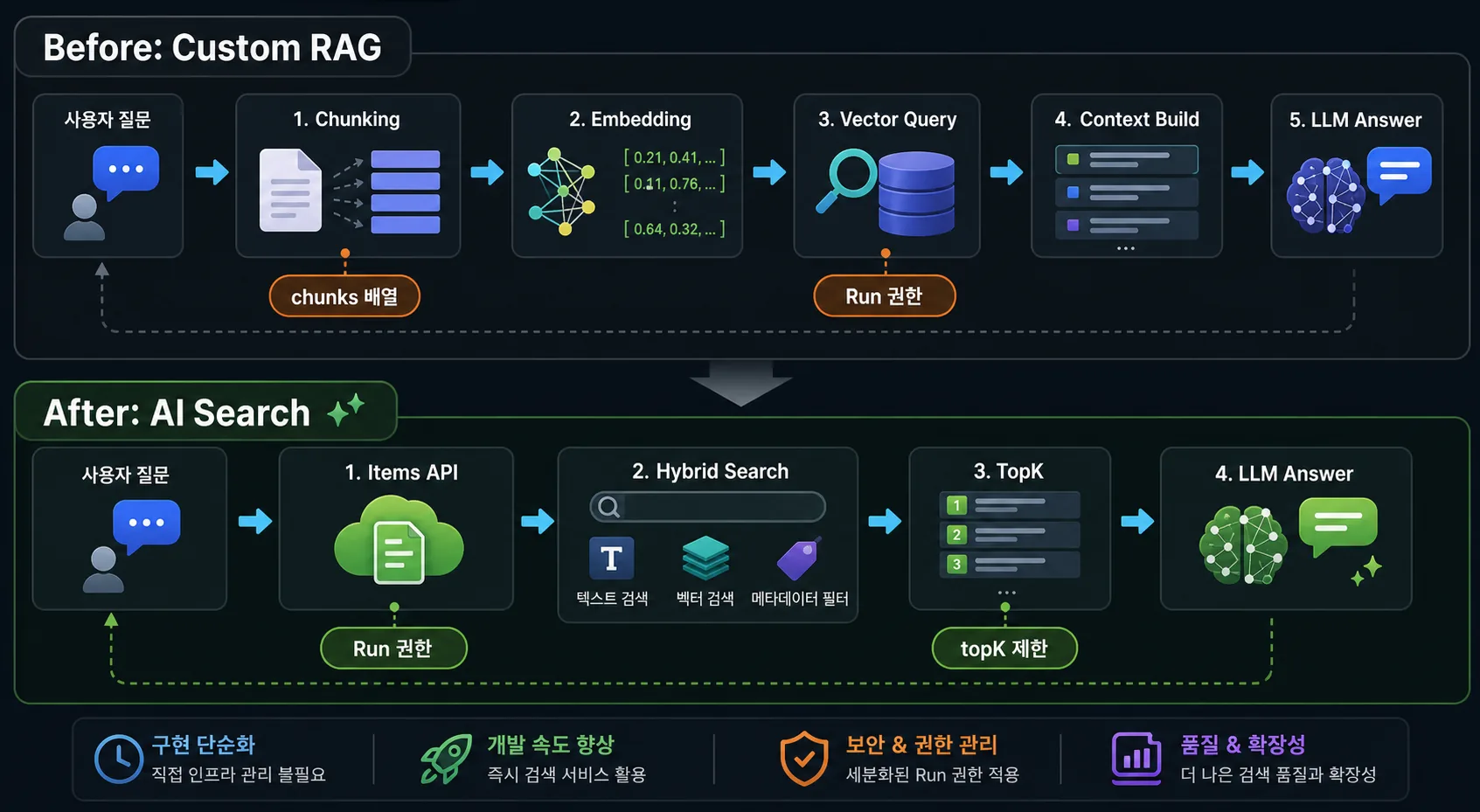 직접 관리하던 RAG 단계가 줄어드는 대신, 권한과 응답 구조를 정확히 이해하는 일이 중요해졌다.
직접 관리하던 RAG 단계가 줄어드는 대신, 권한과 응답 구조를 정확히 이해하는 일이 중요해졌다.
검색 결과 수 제한으로 LLM 과식을 막기
마지막으로 잡은 문제는 문맥 길이였다.
AI Search의 검색 품질이 좋아지니 오히려 너무 많은 후보 문서가 들어왔다. 관련 청크를 많이 가져오는 것은 검색 관점에서는 좋아 보이지만, 그걸 전부 LLM 프롬프트에 넣으면 문제가 생긴다.
문맥이 길어지면 응답이 느려지고, 비용이 늘고, 모델이 핵심 문서를 놓치기도 한다. 심하면 답변 생성이 비어 보이거나 품질이 급격히 흔들릴 수 있다.
그래서 검색 단계에서 상위 결과 수를 제한했다. 예전 RAG 코드에서 말하던 topK 조정과 같은 목적이다. 최신 AI Search API 기준으로는 검색 옵션의 max_num_results 같은 값을 통해 가져올 결과 수를 줄이는 방식으로 이해하면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
const response = await fetch(searchUrl, {
method: "POST",
headers: {
"Authorization": `Bearer ${apiToken}`,
"Content-Type": "application/json"
},
body: JSON.stringify({
messages: [
{ role: "user", content: query }
],
ai_search_options: {
retrieval: {
max_num_results: 3
}
}
})
});
핵심은 단순하다. RAG 챗봇은 많이 찾는 것보다 답변에 쓸 만큼만 정확히 찾는 것이 중요하다.
이번에는 상위 3개 정도로 제한하니 응답이 훨씬 안정적으로 돌아왔다. 위키 챗봇 입장에서는 관련 문서 50개를 억지로 읽는 것보다, 가장 관련 있는 문서 몇 개를 제대로 읽고 답하는 편이 낫다.
바뀐 뒤의 느낌
전환하고 나니 구조가 꽤 가벼워졌다.
예전에는 내가 직접 붙들고 있던 부분이 많았다.
- 문서 청킹
- 임베딩 생성
- 벡터 저장
- 벡터 검색
- 검색 결과 조립
- LLM 프롬프트 구성
AI Search로 옮기면서 이 중 상당 부분을 플랫폼 기능에 맡길 수 있게 됐다. 물론 완전히 신경 쓸 일이 사라진 것은 아니다. API 권한, 응답 포맷, 검색 결과 개수, 모델 문맥 길이는 여전히 직접 보고 조정해야 한다.
그래도 방향은 분명하다.
내가 만들고 싶은 것은 검색 엔진 연구 프로젝트가 아니라, 계속 쓰고 싶은 개인 지식관리 위키다. 그런 관점에서 Cloudflare AI Search는 수제 RAG의 많은 부담을 줄여주는 좋은 선택지로 보인다.
오늘의 교훈
이번 전환에서 얻은 교훈은 세 가지다.
- AI Search REST API 토큰에는
Edit와Run권한을 모두 넣자. - 응답 배열이
results인지chunks인지 방어적으로 처리하자. - LLM에 넘기는 검색 결과는
max_num_results처럼 결과 수 제한 옵션으로 줄이자.
그리고 하나 더.
베타 기능은 문서를 읽는 시간보다 직접 부딪혀 보는 시간이 더 길 수 있다. 그래도 한 번 뚫고 나면 얻는 것이 있다. 수제 RAG로 구조를 이해했고, AI Search로 운영 부담을 줄였다. 두 단계를 모두 거치니 이제 내가 어떤 부분을 직접 만들고, 어떤 부분을 플랫폼에 맡겨야 하는지 감이 더 선명해졌다.
앞으로 이 위키는 단순히 “검색되는 문서 모음”이 아니라, 내가 쌓은 문서를 바탕으로 답하고 정리해주는 LLM 기반 지식관리 도구에 더 가까워질 것 같다.
참고한 공식 문서
이 포스팅이 가치 있었나요?
여러분의 평가는 콘텐츠의 품질을 결정하는
가장 핵심적인 데이터가 됩니다.
실시간 익명 데이터로 수집되어 블로그 운영에 반영됩니다.